오늘날 행해지고 있는 기계학습의 가장 흔한 유형과 이 책의 주요 주제는 컴퓨터가 무엇을 어떻게 배워야 하는지 알려주는 인간의 학습 과정을 지도하는 감독된 학습이다.
감독된 학습을 통해 친구의 사진과 같이 모델을 보면서 훈련할 수 있습니다. 그러나 이러한 예제가 무엇을 나타내는지도 알려줍니다. 그래서 모델이 두 예 간의 차이를 구별하는 법을 배울 수 있습니다. 이러한 레이블은 해당 사진에서 실제로 어떤 사람이 있는지 모델을 나타냅니다. 감독된 교육에는 항상 레이블이 지정된 데이터가 필요합니다.
참고: 때때로 사람들은 예시 대신에 "샘플"이라고 말합니다. 같은 것이다.
감독된 학습의 두 하위 영역은 분류와 회귀입니다.
회귀 기법은 온도, 전력 수요 또는 주식 시장 가격 변동과 같은 지속적인 대응을 예측한다. 회귀 모형의 출력은 하나 이상의 부동 소수점 숫자입니다. 사진에서 면의 존재와 위치를 탐지하려면 면이 포함된 이미지의 직사각형을 설명하는 네 개의 숫자를 출력하는 회귀 모형을 사용합니다.
분류 기법은 이메일이 스팸인지 또는 좋은 개의 사진인지와 같은 별개의 반응 또는 범주를 예측합니다.
분류 모델의 출력은 "좋은 개" 또는 "나쁜 개" 또는 "스팸" 대 "스팸 없음" 또는 친구 중 한 명의 이름입니다. 모델이 인식하는 클래스입니다. 모바일 앱의 대표적인 분류 애플리케이션은 이미지로 사물을 인식하거나 텍스트 한 조각이 긍정적인 정서를 표현하는지 부정적인 정서를 표현하는지를 결정하는 것이다.
또한 인간을 학습 과정에 참여시키지 않는 무감독 학습이라고 불리는 기계 학습의 종류가 있다. 대표적인 예가 클러스터링인데, 이 알고리즘에는 레이블이 없는 데이터가 많이 주어지며, 알고리즘의 역할은 이 데이터에서 패턴을 찾는 것이다. 인간으로서 우리는 전형적으로 어떤 종류의 패턴이 존재하는지 사전에 알지 못하기 때문에 ML 시스템을 안내할 방법이 없다. 응용 프로그램으로는 유사한 이미지 찾기, 유전자 염기서열 분석, 시장 조사 등이 있다.
세 번째 유형은 강화 학습으로, 에이전트가 특정 환경에서 행동할 수 있는 방법을 배우고 좋은 행동에 대해서는 보상을 받지만 나쁜 행동에 대해서는 처벌을 받는다. 이런 종류의 학습은 프로그래밍 로봇과 같은 작업에 사용된다.
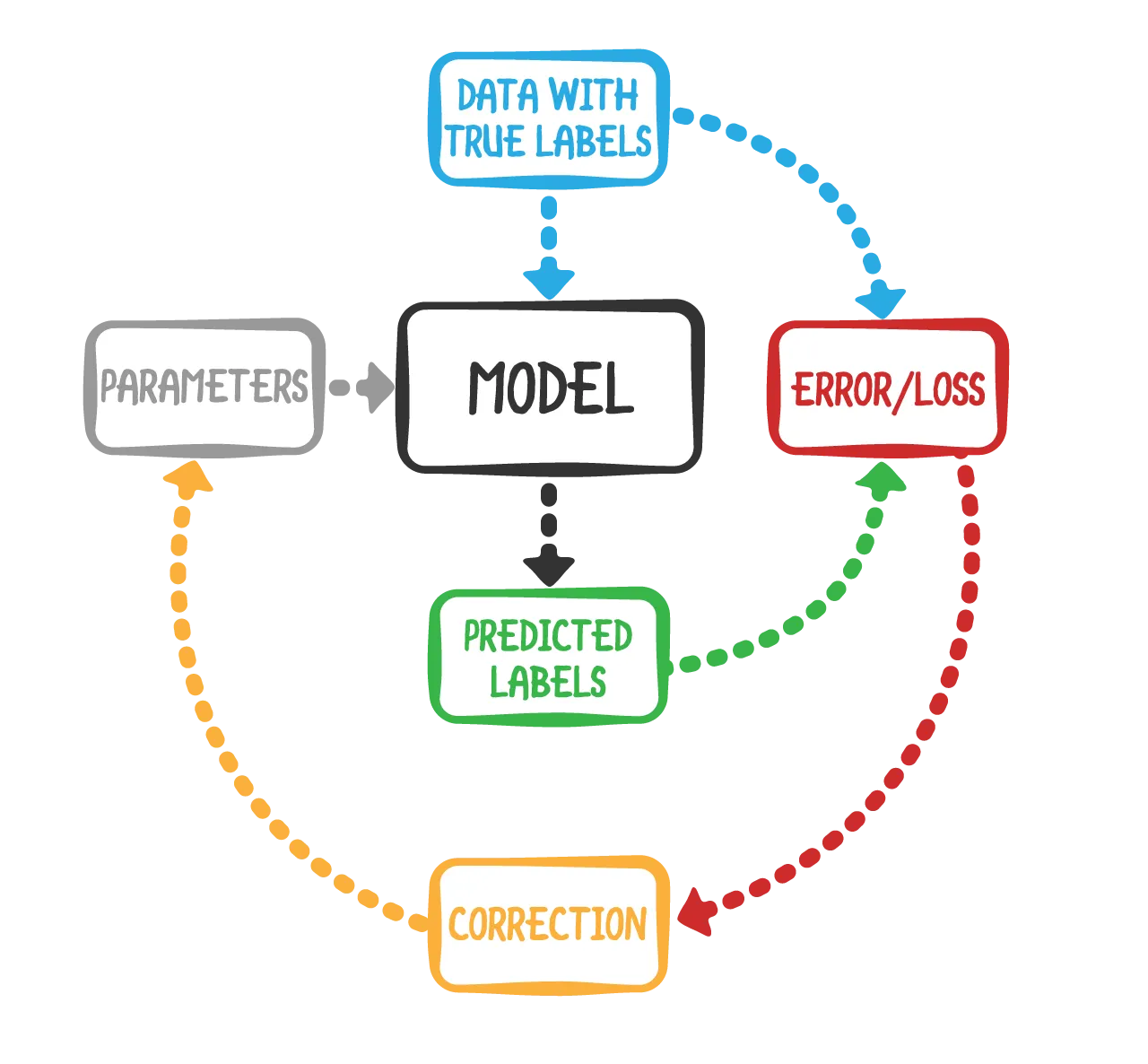
모델이 실제로 학습하는 것은 무엇입니까?
정확히 어떤 모델이 학습하느냐는 선택한 알고리즘에 따라 달라집니다. 예를 들어 결정 트리는 말 그대로 같은 종류의 것을 배운다. if-then-else 인간이 만들었을 법한 규칙들 그러나 대부분의 다른 머신러닝 알고리즘은 규칙을 직접 배우는 것이 아니라 학습된 파라미터 또는 모델의 "패러미터"라고 불리는 숫자의 집합이다.
이 숫자들은 알고리즘이 배운 것을 나타내지만, 우리 인간에게는 항상 말이 되는 것은 아닙니다. 이렇게 단순하게 해석할 수는 없습니다. if-then-else수학은 그것보다 더 복잡하다.
이 모델들이 완벽하게 받아들일 수 있는 결과를 만들어낸다 하더라도, 이 모델들 안에서 무슨 일이 일어나고 있는지 항상 명백하지는 않다. 큰 신경망은 쉽게 5천만 개의 매개변수를 가질 수 있습니다. 그러니 머리를 감싸보세요!
우리가 모델이 훈련 사례를 외우도록 하려는 것이 아니라는 것을 깨닫는 것이 중요합니다. 그건 매개 변수가 아니야 교육 과정 중에 모델 매개변수는 교육 데이터 개요를 유지하지 않고 교육 예제에서 어떤 의미를 포착해야 합니다. 이것은 좋은 예, 좋은 라벨, 그리고 문제에 적합한 손실 함수를 선택함으로써 수행된다.
그러나 기계 학습의 주요 과제 중 하나는 오버핏(overfit)으로, 모델이 특정 교육 사례를 기억하기 시작할 때 발생합니다. 특히 수백만 개의 파라미터를 가진 모델에서는 오버핏을 피하기 어렵습니다.
친구 검출기의 경우, 모델의 학습된 매개변수는 어떻게든 인간의 얼굴이 어떻게 생겼는지, 그리고 어떻게 그것을 사진에서 찾을 수 있는지, 그리고 어떤 얼굴이 어떤 사람의 것인지에 대한 인코딩한다. 그러나 모델은 교육 영상에서 특정 픽셀 값 블록을 기억하지 못하도록 만류해야 하며, 이는 과도한 적합을 초래할 수 있습니다.
어떻게 모델이 얼굴이 무엇인지 알 수 있을까요? 신경망의 경우 모델은 피쳐 검출기 역할을 하며 말 그대로 관심 대상(얼굴)이 아닌 것(다른 것)과 구별되는 방법을 학습하게 된다. 다음 장에서 신경망이 어떻게 이미지를 이해하려고 하는지 살펴보실 겁니다.